
With the rise of open-source, open-weight models and concerns around data sovereignty and data privacy, a lot of people have started to construct and host their own platforms and their own LLMs for their own uses. With open-weight, open-source models, there is much greater control over the LLM deployment, allowing you to tailor your own costs, your own infrastructure, model-size, task specific fine-tuning, security etc. which makes something like vLLM very attractive to individuals, companies and governments.
The current AI/ML data landscape is vast:
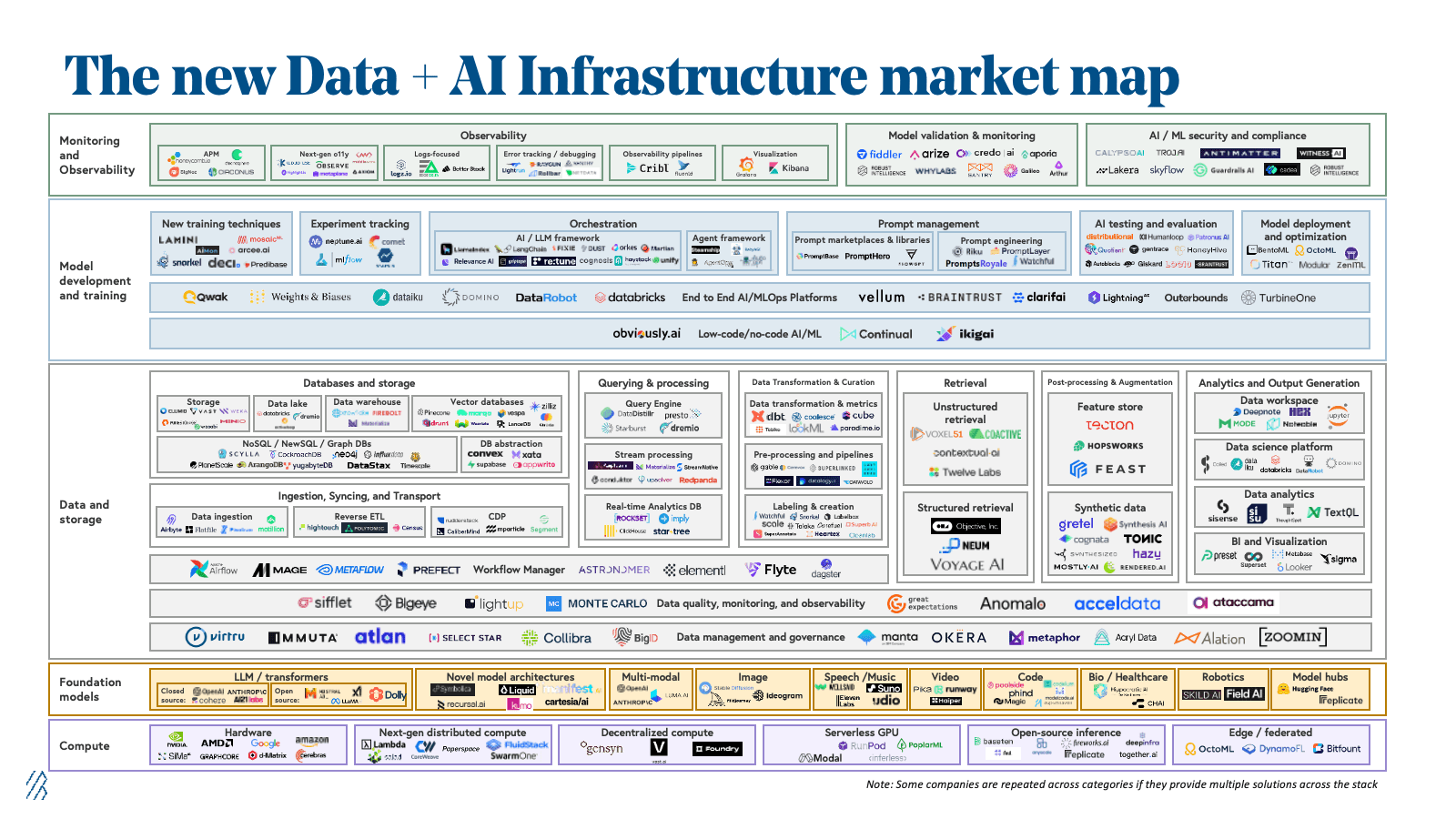
and this vastness is overwhelming for new developers just coming in its something of a Herculean task to understand exactly what's going on. If you're just a poor developer that just wants to use a model, you also kind of don't care what is going on underneath and you just want something to work.
vLLM
vLLM is a high-performance inference and serving engine for LLMs. It is easy to use, easy to setup along with being very memory-efficient and very scalable. vLLM is also highly compatible with multiple GPU vendors whether that be NVIDIA, AMD or Google TPUs.
vLLM is also vendor agnostic so it doesn't care where it's installed, it can be run on AWS, GCP, Windows, Linux, Docker, K8s, etc. so it makes the software extremely flexible whilst also being user friendly and you can deploy models locally with very little hassle.
I've personally been using it over tools like Ollama for local setup because firstly, it is a production ready tool that is designed for high-concurrency and high-throughput which makes it relevant in production and it is also just as easy to setup so I don't see the downside.
There is also plently of clear documentation on the vLLM docs website which makes the whole experience so much more enjoyable to use.
For me, I've been using vLLM to run a local LLM on my Linux home server running on my AMD GPU in a lightweight K8s environment to help me write documentation in a writing style that sounds like me.
Installation
TLDR
vLLM is a high‑performance inference engine for large language models (LLMs). It focuses on fast, memory‑efficient serving of models using techniques like PagedAttention, which reduces memory fragmentation and improves throughput when handling many concurrent requests. It is simple to use, simple to setup and platform agnostic whilst using OpenAI‑compatible API.
I have installed it on my local Homelab in a K8s environment